
Продолжение. Начало — Часть1
Cоздадим в ROS новый проект vp_ardrone1
cd ros_pkgs roscreate-pkg vp_ardrone1 std_msgs rospy
Устанавливаем систему зависимостей
rosdep install vp_ardrone1
Строим проект
rosmake vp
Для преобразования речи в текст будем использовать julius. Julius — движок распознавания речи. Julius был первоначально разработан японским LVCSR в 1997 году, был продолжен CSRC (Continuous Speech Recognition Consortium — Консорциум непрерывного распознавания речи) с 2000 по 2003 год, и в настоящее время разработывается ISTC (Interactive Speech Technology Consortium — Консорциум интерактивных речевых технологий).
Julius требует предварительно обученных грамматической и акустической моделей. На данный момент julius использует внешний движок генерации акустической модели (обучения) HTK, разрабатываемый под руководством Microsoft в Кэмбридже. Акустическая модель строится путем обработки звуковых файлов (с начитанными человеком фрагментами текстов) специальными программами (например, из пакета HTK). Наиболее правильно самому наговорить эти фрагменты и, таким образом, научить движок распознавать именно твой голос (в том числе, интонацию и ошибки произношения) и словосочетания, которые нужны именно тебе. Тогда процент правильного распознавания будет стремиться к значению 100. Однако все это сложно, требует определенной подготовки и времени, поэтому ограничимся акустической моделью, распространяемой с сайта www.voxforge.org. Приемлемая акустическая модель есть для английского языка, для русского пока нет.
Как альтернативу я пробовал и еще пытаюсь пробовать распознование Ardron-ом русской речи с помощью Google Speech API, здесь несколько минусов:
— требуется подключение к интернету
— процент распознования (хотя при использовании Google Search API с планшете распознование гораздо лучше)
— задержка с получением ответа 3-5 сек
Julius есть в репозиториях многих дистрибутивов. В Ubuntu для установки Julius достаточно выполнить команду:
$ sudo aptitude install julius
Для подключения акустической модели foxforge (английский язык) устанавливаем пакет julius-voxforge
$ sudo aptitude install julius-voxforge
Теперь можно приступить к настройке, которая фактически включает в себя только процесс создания словаря: списка слов, который должен уметь распознавать движок, и объяснение того, как эти слова могут между собой сопоставляться. Нужно это для двух целей: во-первых, движок должен знать произношение слов и понимать их, а во-вторых, сократив словарь всего до нескольких фраз, мы значительно повысим качество распознавания. Возьмем стандартные словари, распространяемые вместе с пакетом julius-voxforge
$ cp /usr/share/doc/julius-voxforge/examples/* ~/ros_pkgs/vp_ardrone1/nodes $ cd ~/ros_pkgs/vp_ardrone1/nodes $ gunzip * 2>&1 | grep -v ignored
Файл sample.voca содержит совсем небольшой список слова также их фонетическое представление (что-то вроде транскрипции), файл sample.grammar содержит правила, в каких комбинациях эти слова могут быть использованы.
Сначала определимся со списком слов для голосовых команд управления ArDrone.
1. Выбор объекта, к которому обращены команды (предполагается в связке использовать ArDrone 2.0 и Turtlebot на основе iRobot Create)
«Drone» — квадрокоптер ArDrone 2.0;
«Robert» — робот Turtlebot.
2. Команды приветствия
«Hi»,»Buy»,»Thanks»,»Sleep»
3. Команды выбора действия
«On»,»Off»,»forward»,»back»,»left»,»right»,»up»,»down»,»turn»(поворот),
«hang»(зависнуть),»dance»(предопределенная полетная анимация)
4. Команды параметры выбора действия
«one»-«nine» (1-9) — скорость движения (или номер полетной анимации)
«slow»,»fast» — быстрее, медленнее для скорости
Изменим содержимое файла sample.voca следующим образом
% NS_B
sil
% NS_E
sil
% NAME
DRONE d r ow n
ROBERT r ow b er t
% HELLO
HI hh ay
BUY b ay
THANKS th ae ng k s
SLEEP s l iy p
% DO
ON ao n
OFF ao f
FORWARD f ao r w aa r d
BACK b eh k
LEFT l eh f t
RIGHT r ay t
TURN t er n
UP ah p
DOWN d aw n
HANG hh ae ng
DANCE d aa n s
% DIGIT
ONE w ah n
TWO t uw
THREE th r iy
FOUR f ao r
FIVE f ay v
SIX s ih k s
SEVEN s eh v ax n
EIGHT ey t
NINE n ay n
% SPEED
FAST f aa s t
SLOW s l ow
Фонетическое представление берем из файла beep-1.0 (файл можно будет получить из репозитория проекта (ссылка будет позже)).
Изменим файл sample.grammar (содержит правила, в каких комбинациях эти слова могут быть использованы) следующим образом
S : NS_B FRAZA NS_E
FRAZA: NAME HELLO
FRAZA: NAME DO
FRAZA: NAME DO DIGIT
FRAZA: NAME DO SPEED
FRAZA: HELLO
FRAZA: DO
FRAZA: DIGIT
FRAZA: SPEED
S : NS_B FRAZA NS_E означает, что движок должен понимать словосочетания, которые состоят из: тишина (NS_B), FRAZA , тишина (NS_E). FRAZA — возможные наборы слов. Содержимое файла таково, что можно отдавать не только полные команды
Drone forward five, drone back slow, drone dance slow
но и укороченные (реализуем далее пр помощи сохранения в переменных ROS текущего робота, текущего действия, текущего значения действия), например
forward seven, nine, slow
Выполняем команду для генерации файлов sample.dfa sample.term и sample.dict:
$ mkdfa sample
Тестим julius с помощью команды:
$ padsp julius -quiet -input mic -C julian.jconf
Здесь возникает проблема скрипт зависает и ничего не распознает
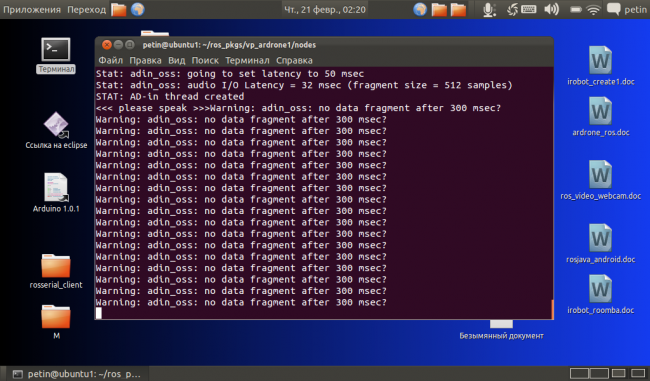
которую пока решить смог только открытием окна Системные -> Параметры системы -> Звук при работе скрипта
И результат работы системы распознавания (см. sentence1)
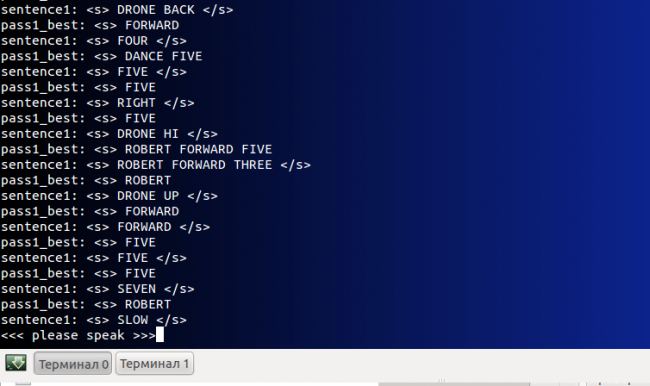
Далее — создание скриптов для ROS — Часть 3
0 комментариев на «“Голосовое управление квадрокоптером ArDrone 2.0 через ROS.Часть 2”»
отличная работа! тоже всё собирался с julius-ом поразбираться, но всё руки не доходят )
насколько хорошо работает распознавание?
я создавал небольшой словарь — работает хорошо
но есть момент — необходимо иметь хорошее произношение, пришлось над этим поработать, хотя до сих пор такие слова как turn (повернуть) очень редко могу произнести правильно (у моих знакомых получается хорошо). И еще команды из нескольких слов — drone back three — необходимо произносить слитно без пауз — но если поработать — получается отлично. В общем, нужно хорошее произношение… Я пробовал в этом проекте и google speech api — там намного хуже.
Хотелось бы конечно подключить голосовой модуль для русского языка — может позже попробую, сразу с наскока не удалось подключить…
При запуске вылетает:
Error: voca_load_htkdict: line 1: word 0 has no phoneme:
> 0 [sil]
Error: voca_load_htkdict: line 2: word 1 has no phoneme:
> 1 [sil]
Error: init_voca: error in reading sample.dict: 2 words failed out of 28 words
ERROR: failed to read dictionary «sample.dict»
ERROR: m_fusion: some error occured in reading grammars
ERROR: Error in loading model
пробовал добавлять пробилы после sil, не помогло