
Нейронная сеть — введение
Принцип обучения многослойной нейронной сети с помощью алгоритма обратного распространения
Рассмотрим процесс обучения нейронной сети с использованием алгоритма обратного распространения ошибки (backpropagation).
Для иллюстрации этого процесса используем нейронную сеть состоящую из трёх слоёв и имеющую два входа и один выход:
здесь, автор считает слои по-другому и не учитывает «2 нейрона» входного слоя

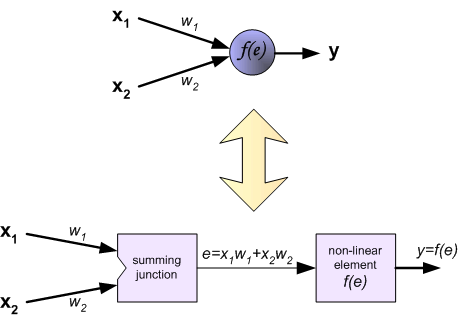
Каждый нейрон состоит из двух элементов.
Первый элемент – дендриты — добавляют весовые коэффициенты ко входным сигналам.
Второй элемент – тело — реализует нелинейную функцию, т.н. функцию активации нейрона.
Сигнал е – это взвешенная сумма входных сигналов
у = f (е)
— выходной сигнал нейрона.
Чтобы обучить нейронную сеть мы должны подготовить обучающие данные(примеры).
В нашем случае, тренировочные данные состоят из входных сигналов (х1 и х2) и желаемого результата z.
Обучение – это последовательность итераций (повторений).
В каждой итерации весовые коэффициенты нейронов подгоняются с использованием новых данных из тренировочных примеров.
Изменение весовых коэффициентов и составляют суть алгоритма, описанного ниже.
Каждый шаг обучения начинается с воздействия входных сигналов из тренировочных примеров. После этого мы можем определить значения выходных сигналов для всех нейронов в каждом слое сети.
Иллюстрации ниже показывают, как сигнал распространяется по сети.
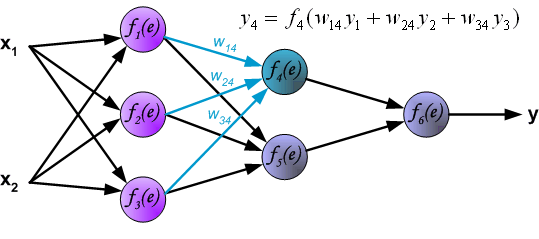
Символы W(Xm)n представляют вес связи между сетевым входом Xm и нейрона n во входном слое.
Символы y(n) представляют выходной сигнал нейрона n.
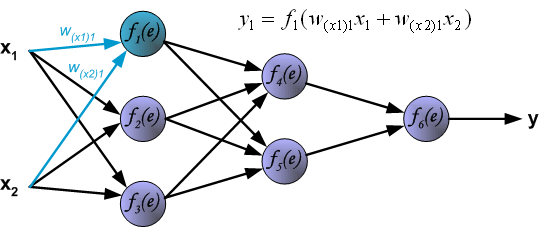
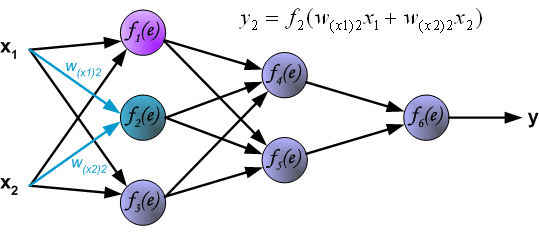
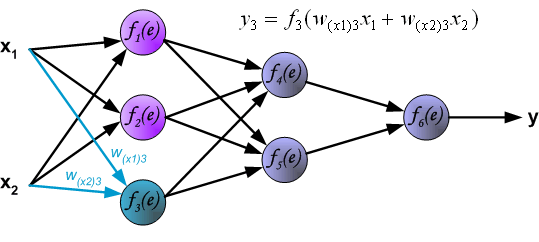
Распространение сигнала через скрытый слой.
Символы Wmn представляют весовые множители связей между выходом нейрона m и входом нейрона n в следующем слое.
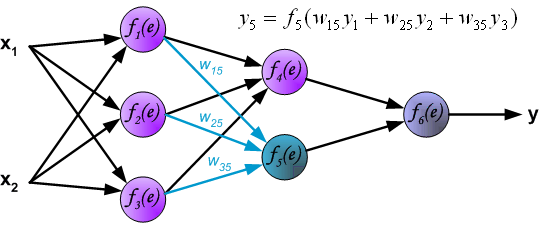
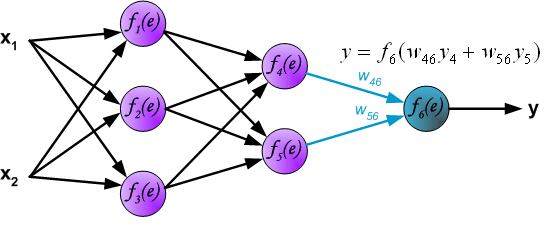
Распространение сигнала через выходной слой
На следующем шаге алгоритма, выходной сигнала сети y сравнивается с желаемым выходным сигналом z, который хранится в тренировочных данных.
Разница между этими двумя сигналами называется ошибкой d выходного слоя сети.
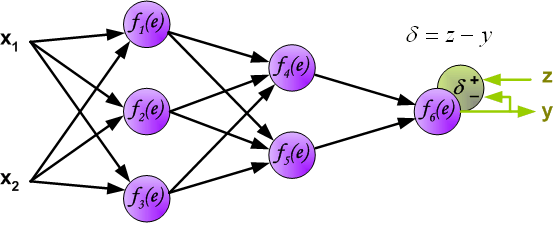
Невозможно непосредственно вычислить сигнал ошибки для внутренних нейронов, потому что выходные значения этих нейронов, неизвестны.
На протяжении многих лет был неизвестен эффективный метод для обучения многослойной сети.
Только в середине восьмидесятых годов был разработан алгоритм обратного распространения ошибки.
Идея заключается в распространении сигнала ошибки d (вычисленного в шаге обучения) обратно на все нейроны, чьи выходные сигналы были входящими для последнего нейрона.
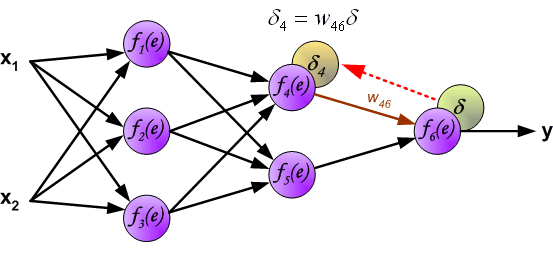
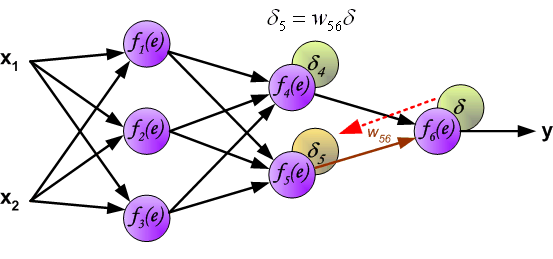
Весовые коэффициенты Wmn, используемые для обратного распространения ошибки, равны тем же коэффициентам, что использовались во время вычисления выходного сигнала. Только изменяется направление потока данных (сигналы передаются от выхода ко входу).
Этот процесс повторяется для всех слоёв сети. Если ошибка пришла от нескольких нейронов — она суммируются:
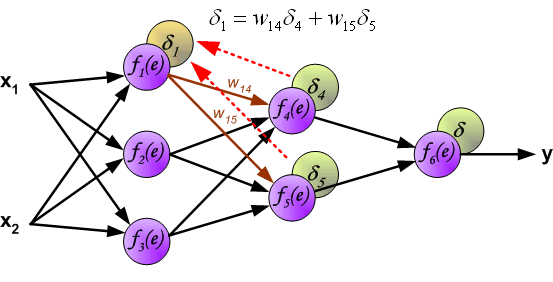
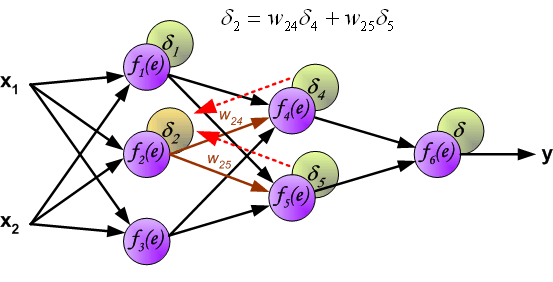
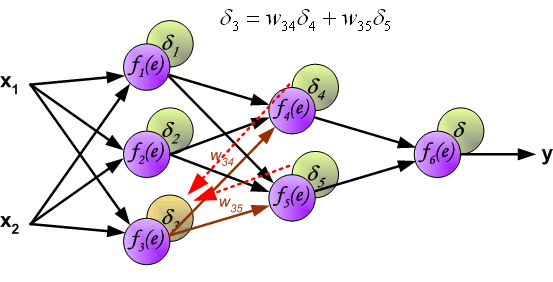
Когда вычисляется величина ошибки сигнала для каждого нейрона – можно скорректировать весовые коэффициенты каждого узла ввода(дендрита) нейрона.
В формулах ниже df(e)/de — является производной от функции активации нейрона (чьи весовые коэффициенты корректируются).
как помним, для активационной функции типа сигмоид
1 S(x) = ----------- 1 + exp(-x)производная выражается через саму функцию:
S'(x) = S(x)*(1 - S(x)), что позволяет существенно сократить вычислительную сложность метода обратного распространения ошибки.
Вычисление производной необходимо, потому что для корректировки весовых коэффициентов при обучении ИНС с помощью алгоритма обратного распространения, используется метод градиентного спуска.
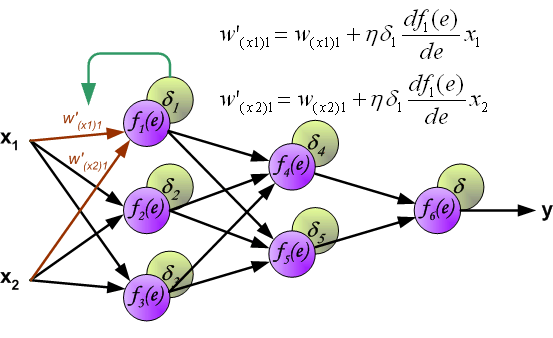
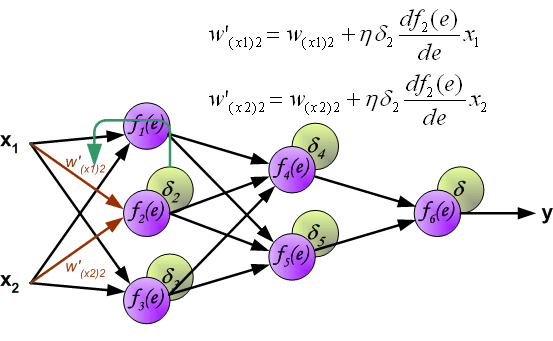
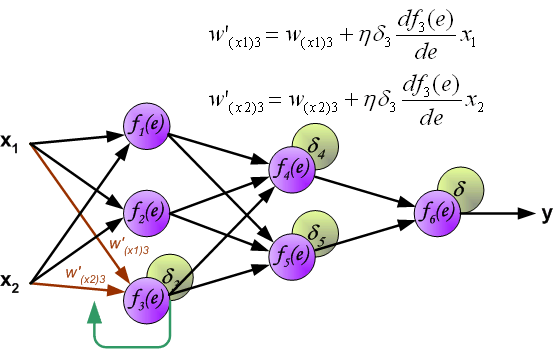
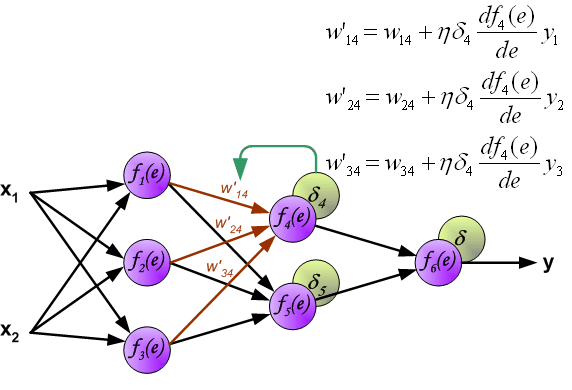
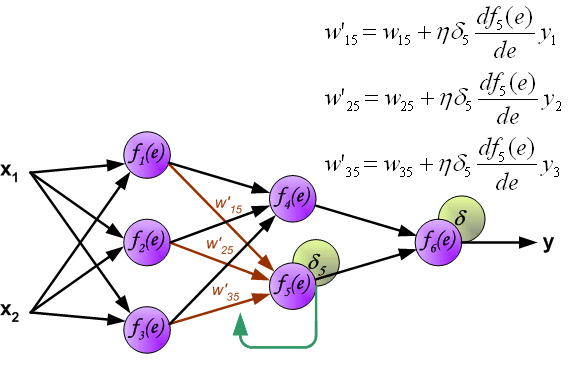
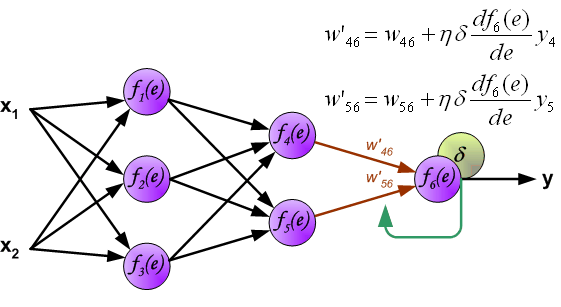
Коэффициент h влияет на скорость обучения сети.
Есть несколько методов для выбора этого параметра.
Первый способ — начать учебный процесс с большим значением параметра h. Во время коррекции весовых коэффициентов, параметр постепенно уменьшают.
Второй — более сложный метод обучения, начинается с малым значением параметра h. В процессе обучения параметр увеличивается, а затем вновь уменьшается на завершающей стадии обучения.
Начало учебного процесса с низким значением параметра h позволяет определить знак весовых коэффициентов.
продолжение следует…
Ссылки
Оригинал статьи (на английском)
http://ru.wikipedia.org/wiki/Метод_обратного_распространения_ошибки
http://en.wikipedia.org/wiki/Backpropagation
Нейросеть в 11 строчек на Python
An overview of gradient descent optimization algorithms
По теме
Нейронная сеть — введение
Пример работы самоорганизующейся инкрементной нейронной сети SOINN
19 комментариев на «“Нейронная сеть — обучение ИНС с помощью алгоритма обратного распространения”»
Спасибо. Наглядно, в той книжке, по которой я изучал, было слишком скучно и без картинок. )))
Ждем продолжение!
СПАСИБО!!! Это мега круто! Пятнадцать минут у монитора заменили семестр целой дисциплины у скучного и серьёзного препода )))
Присоединяюсь к остальным — Ждем продолжение!
здесь, автор считает слои по-другому и не учитывает «2 нейрона» входного слоя автор правильно считает. Входной слой вообще слоем не считается(в многослойных сетях)
Отлично! Огромное спасибо.
А нельзя ли так же доходчиво рассказать про карты Кохонена? Очень хотелось бы не ломая мозгов понять еще один нейро-алгоритм: т.н. «Расширяющийся нейронный газ».
Отлично! Огромное спасибо.
А нельзя ли так же доходчиво рассказать про карты Кохонена? Очень хотелось бы не ломая мозгов понять еще один нейро-алгоритм: т.н. «Расширяющийся нейронный газ».
Вообще, пора уже издать книжку типа «Нейросети Для Чайников». Я бы купил.
Что-то я не понял, когда считаем новый вес, к старому прибавляем произведение шага, ошибки, а вот с производной что-то не понятное написано 🙁 может кто словами написать что там делается?
Идея обучения ИНС, состоит в нахождении весовых коэффициентов синапсов, за счёт распространения сигналов ошибки от выхода ИНС к её входам.
Для корректировки весовых коэффициентов, используется метод , откуда и появляется производная.
Как так выходит на вход подаются определенные значения больше 1, а на результирующем нейроне мы значения прогоняем через сигмоиду и как может выйти что-то больше 1?
Как раз и выходит, что для того чтобы подавать данные на вход ИНС, их предварительно нужно нормировать, чтобы они были представлены числом от 0 до 1.
Спасибо за читабельную статью! =) Не могу понять, w’=w + h * D * f'(e) *x, правильно ли я написал формулу, если да, то что вставлять вместо E в f'( )?
Всё конечно очень здорово, но есть одно «НО». При расчёте делта её нужно умножать на производную от функции активации, в связи с чем дельта4, дельта5 и т.д. будут рассчитаны неверно.
Поясните пожалуйста, почему?
Стоит добавить, что в таком виде сеть, как правило, не используется. Необдходимо добавить порог срабатывания (нейроны «смещения»). Без них вряд ли удастся обучить сеть даже простому XORу, не говоря уже о более сложных задачах.
Абсолютно верное замечание.
Исходя из формулы расчета ошибки и формулы расчета нового веса, получается, что если изначально сгенерировать матрицу с нулевыми весами, то её не получится обучить?
w46 = 0
d4 = w46*d6 = 0
Подставляем ноль в формулу вычисления нового веса, где происходит умножение производной от взвешенной сумму на вход и на ошибку, и снова получаем ноль. Вес не поменяется. Я где-то ошибся?
Правильное замечание.
Как уже отметили выше — в данной схеме не хватает сигнала смещения/сдвига (bias) для каждого нейрона (слоя).
Bias характеризует значение в нуле (т.е. выполняет «смещение» результата, когда x=0).
Трудно вспоминать школьный курс по физ.мату если с ним не работал около 10 лет… Но все же очень хочу разобраться: Я проанализировал все по-пунктам (может что-то упустил). описан функционал под уже обученную сеть? Как на первом значении для обучения получить вес W, если на примере сети
(кол-во нейронов в слое) ми имеем всего лишь
4 нейрона.
Разбираю пока на примере линейной зависимости без порога активации: