
В этой статье мы рассмотрим простейшие функции для работы с контекстом процессов и напишем простое многопоточное приложение для Ардуино.
1. Часть первая. Немного о многозадачности, ОС и контроллерах.
Вытесняющие операционные системы позволяют запускать на одном вычислительном ядре несколько не связанных между собой процессов. При этом, такие процессы, в отличие от кооперативных ОС, ничем не отличаются по стилю написания от своих однопоточных собратьев. Для микроконтроллеров такие операционные системы есть. Хотя бы та же FreeRTOS.
Операционная система – штука сложная. В центре ОС стоит диспетчер.
Диспетчер задач — это центральное звено ОС. Он рулит системой. Он раздаёт приоритеты процессам. Вызывает их в ему ведомом порядке. Дарует и отбирает управление. Диспетчер — это такой унылый программный бюрократ. Он выглядит важно и помыкает.
Но эти страшные штуки, приоритеты, планировка… Часто бывают избыточны для проектов на микроконтроллерах.
Вытесняющая многозадачность основывается на работе с контекстом процессов, на их сохранении и загрузке. В случае программирования для микроконтроллеров AVR (и, соответственно Arduino), эти вещи вполне обозримы и несложны для рядового пользователя. Это позволяет добавлять функции работы с контекстами процессов непосредственно в свои проекты.
Функции работы с контекстом – это как кирпичик. С помощью него можно построить дом «ОС»… Но им же можно и подпереть бочку.
Дом строить не будем. Бочку подопрём.
В рамках данной статьи я постараюсь доходчиво рассказать о нескольких внешне малосвязанных вещах.
Мы покричим на компилятор, шарахнемся от препроцессора, обманем среду Arduino, поймём инлайновость, помедитируем над Ассемблером, покиваем на соглашения языка Си, полазим в оперативке микроконтроллера и даже пнём опальный оператор goto… А под конец превратим ШИМ AVR в настоящий, хотя и простейший ЦАП (но это на сладкое, как лёгкий бонус)…
Что мы получим в результате? Написав пару простых функций на Ассемблере, и чуть-чуть сишного кода, мы получим пользовательскую библиотеку, позволяющую писать двухпоточные приложения. Или же одновременно с минимальными изменениями запускать два однопоточных приложения на одном контроллере. А так же рассмотрим пару примеров.
Почему ДВУХПОТОЧНУЮ? Потому что это наиболее просто. Понимая механизм работы простой библиотеки, не составит большого труда дополнить ее и создать на ее основе более сложную.
САМОЕ ГЛАВНОЕ — понимание того, что это не сложно. А это действительно так и дорогого стоит.
2. Часть вторая, подготовительная.
Установим немного конкретики.
Представленные ниже функции написаны под контроллер ATmega168 для среды разработки arduino-1.0.1. Никакими значимыми функциями среды Arduino при этом мы пользоваться не будем (до момента рассмотрения последнего примера), то есть, Arduino, вообще говоря, и не обязательна. Обычного WinAvr и ATmega168 вполне хватило бы.
Оформлять работу будем в виде пользовательской библиотеки. Для этого идем в \arduino-1.0.1\libraries и создаем там специальную папку. У меня это «\arduino-1.0.1\libraries\MirmPS» в эту папку положим потом несколько файлов. (подробнее о создании библиотеки смотри сюда).
Поставим задачу так: «Хочу, чтобы вместо одной циклической функции loop в скетче Ардуино можно было прописать loop1 и loop2, а также, чтобы контроллер выполнял их в режиме вытесняющей многозадачности. Для начала хотя бы по прерыванию от таймера».
3. Часть третья, микроконтроллерно-стековая.
Для того, чтобы понять изложенный здесь материал необходимо кое что знать.
Например, что такое контекст процесса.
Нужно немного представлять, внутреннюю архитектуру ядра AVR. Надо знать о существовании 32-х регистров общего назначения. Понимать, что регистр SREG важен, а также знать, что такое стек.
Так как основным нашим инструментом будет работа со стеком, я начну с того, что о нем напомню.
Стек это область оперативной памяти, в которую можно что-то положить, чтобы это что-то потом оттуда достать. Самая, на первый взгляд, значимая функция стека — сохранение точек входа подпрограмм (я буду называть их функциями). Когда программа вызывает функцию, контроллер сохраняет информацию о том, откуда сделан вызов. Выход из функции осуществляется путем извлечения этого «обратного адреса» и возвращения по нему. «Обратный адрес», он же «точка вызова подпрограммы», хранится в стеке в виде 16-ти битного числа (2 раза по байту). Если программа вызывает функцию, которая вызывает вторую функцию, в стек сначала попадает точка вызова первой, а затем второй функции. Обратный переход разрешается, как не трудно догадаться, в обратном порядке. Это называется LIFO (англ. last in — first out, «последним пришёл — первым вышел»).
То есть, фактически, стек – это вспомогательный массив в который постоянно записываются и из которого извлекаются адреса возвратов и другая информация, если ее необходимо ненадолго сохранить. Со стеком работает специальный 16-битный регистр, который называется указатель стека (Stack Pointer). Он показывает текущее место, в которое стек пишет и из которого читает. Если в стек пишут, указатель автоматически декрементируется. Читают — инкрементируется. При желании указатель стека можно программно переставить в другое место, чтобы обойти правило LIFO, или же вообще создать второй стек.
Отличительной особенностью стека (в контроллерах AVR) является то, что стек нарастает в порядке от старших адресов к младшим.
Теперь немного об оперативной памяти контроллера. Давайте посмотрим на картинку:
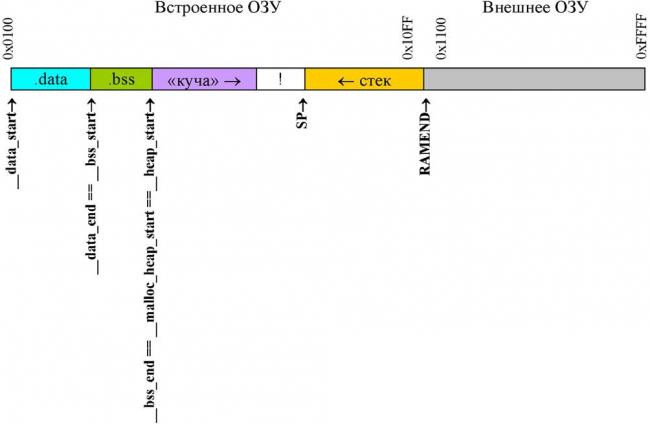
Картинка показывает нормальное распределение памяти для контроллера AVR. Внешнего ОЗУ у нас не будет. Области .data и .bss это то место, где компилятор велит хранить переменные. Обсуждение этих областей лежит вне тематики настоящего изложения.
Остаются «куча», «стек» и непонятный знак восклицания.
Куча — это пространство, в котором ничего нет. Предполагается, что эта часть используется для динамического распределения памяти, если таковое используется в программе, причем сначала распределяются младшие адреса. Пару слов об этом я еще скажу в самом к конце.
«Знак восклицания» — это небольшая уловка, чтобы стек не залез в кучу. Понимать его не обязательно, но отметить для себя надо следущее: динамическая память распределяется слева направо, а стек нарастает справо налево. Если они встретятся будет логический коллапс программы…
Итого картина такая:
Внешнего ОЗУ нет. .data и .bss — место где лежат переменные. Их трогать нельзя. На месте кучи и восклицательного знака пустое место. Его трогать можно. Справа стек. Стек растет налево. От старших адресов к младшим.
Пойдем дальше. Контекст процесса — это информация, о точке текущей выполнения процесса, а так же информация о состоянии контроллера, которая необходима, чтобы процесс выполнялся правильно. Если мы сохраним контекст, а потом через какое-то время загрузим его назад, то программа, как ни в чем не бывало, продолжит работу с того места, на котором прервалась. Собственно, это и есть наилучшее определение контекста. То, что надо сохранить для корректного возобновления процесса – контекст процесса.
Как вы знаете программа для процессора – это список инструкций. Это как длинный свиток, на котором языком доступным процессору по пунктам объясняется чего ему делать. Процессор выполняет инструкцию и переходит, либо к следующей инструкции, либо к какой-то иной, если так велено предыдущей инструкцией. Каждая строчка в этом свитке пронумерована. Номер той строчки которую процессор выполняет прямо сейчас храниться в Programm Counter и называется, допустим, адресом текущей инструкции.
Логично предположить, что при остановке процесса и передаче управления другому процессу, самое главное сохранить именно адрес текущей инструкции (состояние Programm Counter), но одного этого недостаточно. Также необходимы 32 регистра общего назначения, регистр SREG, указатель стека (Stack Pointer) и сам стек, ибо они несут в себе информацию, которую процесс уже обработал, или же, с которой он работал прямо на момент останова. Без этих элементов программа логически развалиться (может и не развалиться, если очень повезет). При желании можно добавить к контексту что-нибудь еще, например состояние периферии или каких-либо переменных, если это необходимо.
SREG — статусный регистр. Достаточно знать, что он важен для правильного выполнения условных операторов и операторов цикла. Также там храниться флаг глобального разрешения прерываний.
Так как же сохранить процесс?
Вообще-то тут есть варианты.
Мы сохраним контекст процесса путем запихивания его в стек и сохранения того адреса, по которому из стека контекст потом можно будет извлечь (указателя стека). Указатель стека будем хранить как обычную переменную. Соответственно в той самой области, которая .data и .bss….
Но это то, что касается одного процесса. Для второго процесса мы искусственно сделаем второй стек. Что-бы не очень углубляться в адресную математику, для простоты, закинем его в середину пустой области памяти. В кучу.
И будет у нас два стека. По стеку под каждый процесс.
4. Часть четвертая, в которой мы дорвёмся до ассемблера и напишем немного макросов.
Ассемблер — очень простой язык. Потому что без выпендрежа. Но писать на нем сложно. Потому что все надо расписывать подробно.
Вам несомненно известно, что человек умеет брать кружку.
Потянуться к кружке. Взять. Это Си.
Когда и какую мышцу напрячь, сгибать ли пальцы, куда смотреть, как определить, что рука приблизилась к кружке… И конечно, не забывать дышать. Это ассемблер.
Он подробный. Но простой.
Для затравки напишем простую функцию, которая будет для нас сохранять часть контекста (32 регистра общего назначения и регистр SREG).
(За подробностями по ассемблеру языка AVR я отсылаю вас к замечательной книжке: «Микроконтроллеры AVR практикум для начинающих», автор В.Я.Хартов)
Вот код. Он не для программы. Он для анализа :
push r0 ; push r0 – директива, командующая положить в стек ; содержимое регистра r0. in r0, SREG ; Теперь запишем в регистр r0 состояние регистра SREG push r0 ; и сохраним его. push r1 ; Сохраняем содержимое r1 clr r1 ; Очищаем регистр r1 push r2 ; push r3 ; push r4 ; push r5 ; push r6 ; push r7 ; push r8 ; push r9 ; И push r10 ; по push r11 ; очереди push r12 ; сохраняем push r13 ; все push r14 ; регистры push r15 ; push r16 ; push r17 ; push r18 push r19 push r20 push r21 push r22 push r23 push r24 push r25 push r26 push r27 push r28 push r29 push r30 push r31 ; всё…
(Примечание: очищение регистра r1 – это дань соглашениям языка Си, по которым r1 всегда должен содержать константу 0x00. Почистить его не вредно, хотя в рамках нашей библиотеки — избыточно.)
Просто?… Думаю да.
Теперь этот код надо как-то встроить в нашу программу. (Да, программы еще нет, но продумать этот момент можно уже сейчас).
В языке Си предусмотрено два основных способа работы с подпрограммами. Если коротко, инлайнить и не инлайнить. Разниться такова. Инлайновая функция — это не подпрограмма. Это просто кусок кода, который компилятор подставит вместо вызова подпрограммы. Неинлайновая функция — это подпрограмма. Встретив вызов, программа передает управление подпрограмме, и в дальнейшем управление передается назад на точку вызова по адресу сохраненному в стеке. При программировании на языке высокого уровня разница в скорости выполнения и занимаемой памяти…. То есть, в общем, никакой…
А вот для нас разница есть. Адрес точки возвращения. Дело в том, что положив адрес в стек при вызове подпрограммы, мы будем потом вынуждены его считать, чтобы вернуться. А над ним сохранены состояния 32 регистров общего назначения, да SREG затесался (помните про LIFO?). Обойти их, конечно можно, но зачем?… Будем инлайнить.
В Си инлайновые ассемблерные функции принято описывать в виде макроса, ссылающегося на ассемблерную вставку. (О макросах читайте в интернете, а про ассемлерную вставку можно сюда сюда)
Выглядит это так (прошу заметить, что это уже не ассемблер. Это Си… ):
#define saveContext() \ //#define saveContext() – объявление макроса asm volatile ( "\n\t" \ //asm – расширение, указывающее на "push r0 \n\t" \ //ассемблерную вставку. volatile – просьба к "in r0, __SREG__ \n\t" \ // компилятору не зазнаваться и руками не "push r0 \n\t" \ //трогать. Это на всякий случай. "push r1 \n\t" \ "clr r1 \n\t" \ "push r2 \n\t" \ "push r3 \n\t" \ "push r4 \n\t" \ // "push r4 \n\t" \ - ассемблерный листинг "push r5 \n\t" \ // передается как строка. кавычки ограничивают "push r6 \n\t" \ // \n\t – указывает на переход строки внутри "push r7 \n\t" \ // команды asm. "push r8 \n\t" \ // внешняя косая черта – относится к макросу. "push r9 \n\t" \ // Это своеобразная конкатенация. "push r10 \n\t" \ "push r11 \n\t" \ "push r12 \n\t" \ "push r13 \n\t" \ "push r14 \n\t" \ "push r15 \n\t" \ "push r16 \n\t" \ "push r17 \n\t" \ "push r18 \n\t" \ "push r19 \n\t"\ "push r20 \n\t" \ "push r21 \n\t" \ "push r22 \n\t" \ "push r23 \n\t"\ "push r24 \n\t" \ "push r25 \n\t" \ "push r26 \n\t" \ "push r27 \n\t" \ "push r28 \n\t" \ "push r29 \n\t"\ // всё… "push r30 \n\t" \ "push r31 \n\t");
Итак, лёд тронулся. У нас есть первый макрос. Он рабочий. Конечная программа будет его использовать. Давайте в догонку сразу же рассмотрим и обратную функцию, загружающую ранее сохраненные 32 регистра и SREG:
И здесь всё тоже самое, только в обратном порядке…
#define loadContext() \
asm volatile ("\n\t" \
"pop r31 \n\t" \
"pop r30 \n\t" \
"pop r29 \n\t" \
"pop r28 \n\t" \
"pop r27 \n\t" \
"pop r26 \n\t" \
"pop r25 \n\t" \
"pop r24 \n\t"\
"pop r23 \n\t" \ // директива pop – это извлечение из стека
"pop r22 \n\t" \
"pop r21 \n\t" \
"pop r20 \n\t" \
"pop r19 \n\t" \
"pop r18 \n\t" \
"pop r17 \n\t" \
"pop r16 \n\t" \
"pop r15 \n\t" \
"pop r14 \n\t"\
"pop r13 \n\t" \
"pop r12 \n\t" \
"pop r11 \n\t" \
"pop r10 \n\t" \
"pop r9 \n\t" \
"pop r8 \n\t" \
"pop r7 \n\t" \
"pop r6 \n\t" \
"pop r5 \n\t" \
"pop r4 \n\t"\
"pop r3 \n\t" \
"pop r2 \n\t" \
"pop r1 \n\t" \
"pop r0 \n\t" \
"out __SREG__, r0 \n\t" \
"pop r0 \n\t");
Тут уже всё знакомо.
Теперь давайте создадим в нашей библиотеке файл «.h» у меня это «MirmPS.h» и добавим туда 2 готовых макроса.
Итого, мы сохранили регистры общего назначения и статусный регистр. По плану еще Programm Counter, Stack Pointer, и сам стек.
Стек сохранять не будем. Действительно, а как его сохранять, если сохраняем мы в нем. Его сохранность гарантируется тем, что его не трогают, пока не позволено. Сохранение Programm Counter — это отдельная тема. Об этом позже.
Stack Pointer — это просто. Указатель стека состоит из двух регистров. SPH и SPL. Надо создать переменные, в которых мы будем их хранить для каждого процесса. И немного макросов для работы с ними. Еще немного кода:
typedef volatile union Spt //Определяем тип для хранения
{int i; //StackPointer; Определение
char c[2]; //на основе union позволит
} SPstore_t; //обращаться со значением
//и как с int и как с char[2]
extern SPstore_t SPstore[2]; //Определение массива на два указателя
//прямая установка StackPointer.
#define setStackPointer(x,y) {SPH=x;SPL=y;}
//макросы для работы с SPstore. Запись и Чтение.
#define copyStackPointer(x) {x.c[1]=SPH;x.c[0]=SPL;}
#define loadStackPointer(x) {SPH=x.c[1];SPL=x.c[0];}
Что такое union можно почитать в интернете.
copyStackPointer и loadStackPointer работают на тип SPstore_t. Такая странная декларация типа нужна, чтобы было проще извлекать SPL и SPH по отдельности, но в то же время иметь возможность работы с полным указателем стека.
volatile — это просьба компилятору не трогать ничего без надобности, а extern — указание на то, что SPstore[2] будет использоваться в каком-то другом файле.
Теперь полный код MirmPS.h:
#include "MirmPS_assemf.h"
#ifndef Mirm_PS_h //Защита от двойного подключения
#define Mirm_PS_h
typedef volatile union Spt //Определяем тип для хранения
{int i; //StackPointer; Определение
char c[2]; //на основе union позволит
} SPstore_t; //обращаться со значением
//и как с int и как с char[2]
extern SPstore_t SPstore[2]; //Определение массива на два указателя
//прямая установка StackPointer.
#define setStackPointer(x,y) {SPH=x;SPL=y;}
//макросы для работы с SPstore. Запись и Чтение.
#define copyStackPointer(x) {x.c[1]=SPH;x.c[0]=SPL;}
#define loadStackPointer(x) {SPH=x.c[1];SPL=x.c[0];}
#define saveContext() \ // Макрос сохранения контекста.
asm volatile ( "\n\t" \
"push r0 \n\t" \
"in r0, __SREG__ \n\t" \
"push r0 \n\t" \
"push r1 \n\t" \
"clr r1 \n\t" \
"push r2 \n\t" \
"push r3 \n\t" \
"push r4 \n\t" \
"push r5 \n\t" \
"push r6 \n\t" \
"push r7 \n\t" \
"push r8 \n\t" \
"push r9 \n\t" \
"push r10 \n\t" \
"push r11 \n\t" \
"push r12 \n\t" \
"push r13 \n\t" \
"push r14 \n\t" \
"push r15 \n\t" \
"push r16 \n\t" \
"push r17 \n\t" \
"push r18 \n\t" \
"push r19 \n\t"\
"push r20 \n\t" \
"push r21 \n\t" \
"push r22 \n\t" \
"push r23 \n\t"\
"push r24 \n\t" \
"push r25 \n\t" \
"push r26 \n\t" \
"push r27 \n\t" \
"push r28 \n\t" \
"push r29 \n\t"\
"push r30 \n\t" \
"push r31 \n\t");
#define loadContext() \ // Макрос загрузки контекста.
asm volatile ("\n\t" \
"pop r31 \n\t" \
"pop r30 \n\t" \
"pop r29 \n\t" \
"pop r28 \n\t" \
"pop r27 \n\t" \
"pop r26 \n\t" \
"pop r25 \n\t" \
"pop r24 \n\t"\
"pop r23 \n\t" \
"pop r22 \n\t" \
"pop r21 \n\t" \
"pop r20 \n\t" \
"pop r19 \n\t" \
"pop r18 \n\t" \
"pop r17 \n\t" \
"pop r16 \n\t" \
"pop r15 \n\t" \
"pop r14 \n\t"\
"pop r13 \n\t" \
"pop r12 \n\t" \
"pop r11 \n\t" \
"pop r10 \n\t" \
"pop r9 \n\t" \
"pop r8 \n\t" \
"pop r7 \n\t" \
"pop r6 \n\t" \
"pop r5 \n\t" \
"pop r4 \n\t"\
"pop r3 \n\t" \
"pop r2 \n\t" \
"pop r1 \n\t" \
"pop r0 \n\t" \
"out __SREG__, r0 \n\t" \
"pop r0 \n\t");
#endif
#include «MirmPS_assemf.h» — Это для того чтобы подключить еще одну ассемблерную функцию. Она будет уже настоящей, не инлайновой. Но это чуть позже.
MirmPS.h можно заворачивать и не трогать.
5.Часть пятая, в которой мы переписываем main функцию.
Я думаю, для вас не секрет, что скетч, который пишется для создания проекта на Arduino, не что иное как полуфабрикат, который перед линкованием вставляется в main.cpp, лежащий в папочке cores. И именно main.cpp, а не скетч, по сути, является основной программой.
И мы его перепишем. Но сделаем это аккуратно. Разработчики Arduino толи специально, то ли по недосмотру дали пользователю возможность переписывать системные функции без изменения библиотек ядра.
Дело в том, что при линковании и компиляции все функции, лежащие в папке hardware/arduino/cores собираются и архивируются в статическую библиотеку core.a (подробности смотри в логах компиляции), а пользовательские библиотеки не архивируются.
Если не вдаваться в подробности, то у статической библиотеки низкий приоритет относительно не архивированных файлов.
Это даёт нам возможность скопировать main.cpp из hardware/arduino/cores в папку нашей пользовательской библиотеки. Отныне функция main будет читаться отсюда. Здесь мы ее и перепишем.
Примечание: Что очень полезно, это верно только в случае, если в скетче будет подключена пользовательская библиотека, содержащая замененную функцию. Таким образом для отключения функции и возвращения к ядровому варианту будет достаточно не подключать соответствующую пользовательскую библиотеку. Это даёт пользователю богатые возможности по гибкому модифицированию ядра Arduino.
Итак, копируем main.cpp из hardware/arduino/cores в папку нашей пользовательской библиотеки.
Пусть основная часть кода в функции main выглядит так:
void loop1(void);
void loop2(void); //Функции реализованы в скетче.
void setup(void);
int main(void) //Точка входа программы.
{
init(); //Настройка ядра Ардуино. В основном таймеры.
cli(); //init() разрешает прерывания. но
//нам они пока не нужны. Запретим.
branching();//Ветвитель потоков.
return 0; //Сюда программа не попадёт.
}
volatile void programm1(void){ //А это два наших потока.
setup(); sei(); //Первый поток вызывает также cодержит
for (;;) {loop1(); //функцию setup.И разрешает прерывания.
}
} //За их вызов ответственна
volatile void programm2 (void){
for (;;) {loop2();} //функция branching()
}
Таким образом:
Порядок действий такой. Инициализация ядра Arduino. Отключение прерываний, которые функция инициализации слишком рано включает и тут же вызов функции branching().
Что это такое? Это ветвитель. Коротенькая подпрограмма, который превращает один поток в два. Для этого ветвитель сохраняет исходный поток и копирует сохраненный поток на новое место, запоминая новый адрес. Теперь потоков будет два и они одинаковые. Далее он передает управление первому потоку. Ветвитель устроен таким образом, что первый и второй потоки, будучи одинаковыми на момент создания, имеют разные точки выхода из функции. Точка выхода первого потока из ветвителя — функция programm1. Второго — programm2.
6. Часть шестая, заумная, в которой мы понимаем работу ветвителя.
На практике всё немного сложнее, чем в теории. Системой команд AVR не предусмотрено директив, позволяющих напрямую скопировать содержимое счетчика команд (Programm Counter). А нам нужно его скопировать, да еще таким образом, чтобы потом можно было загрузить. Проблема эта обходится.
Мы сделаем это, подсунув программе специальную функцию, при входе в которую содержимое счётчика автоматически копируется в стек. Тут то мы его и возьмём.
Наверное, ветвитель — это самая главная и из-за проблем с доступом к авровскому счетчику команд — самая не очевидная функция в этой библиотеке. Его работу я постараюсь разобрать подробно.
Код:
volatile SPstore_t SPstore[2]; // Здесь храняться указатели стека
// сохраненных потоков.
volatile int Taskcount=0; // Это счетчик выходов из ветвителя.
void branching(void)__attribute__((always_inline));
void branching_2 (void)__attribute__((naked,noinline));
void branching(void)
{ setStackPointer(0x04,0xFF); // установка SP в RAMEND
branching_2(); // точка вызова процедуры
// копирования.
//В эту точку возвращаются новые потоки.
//векторы выхода потоков из ветвителя:
if (Taskcount==0) {Taskcount++;goto *programm1;}
if (Taskcount==1) {Taskcount++;goto *programm2;}
}
void branching_2 (void)
{ saveContext(); //Сохраняем
SPstore[1].i=copyContext(0x040A); //Копируем
loadContext(); //Загружаем
//т.к. функция naked, нужно явно объявить возврат
asm("ret"); //Возвращаемся.
}
Начнем с простого. volatile SPstore_t SPstore[2]; — это старый знакомый. Он был определен в файле MirmPS.h. В него мы будем писать сохраненные указатели стека.
volatile int Taskcount=0; — это переменная на основе значения которой будет произведена процедура ветвления.
Далее сразу же бросается в глаза нестандартная декларация функций
void branching(void)__attribute__((always_inline)); void branching_2 (void)__attribute__((naked,noinline));
Компилятор GCC, используемый средами Arduino и WinAVR понимает специальное ключевое слово __attribute__, которое используется для подсоединения различных атрибутов к функциям, определениям, переменным и типам. Это ключевое слово сопровождается спецификацией атрибута в двойных круглых скобках. Аттрибуты — это указания компилятору на то, как именно следует обработать данную функцию тип или переменную.
Перечень аттрибутов можно посмотреть здесь
Начнем со второй функции __attribute__((naked,noinline)).
__attribute__((naked)) это запрет компилятору оформлять точку вызова функции операциями сохранения регистров. По умолчанию, вызов функции оформляется сохранением некоторого контекста. Какого. Нужного. Компилятор знает какого… Я не знаю… А мне надо работать со стеком и я не хочу, чтобы в стеке был мусор… Поэтому то и naked. __attribute__((noinline)) запрещает компилятору делать функцию инлайновой. Зачем оно надо, я только что рассказал, ведь branching_2 — это та подставная функция, что позволит распотрошить счетчик команд.
Теперь первая функция.
Аттрибут always_inline приказывает компилятору встроить функцию вместо ее вызова. Если модификатор inline — это скорее просьба то always_inline — это приказ.
Есть, правда, одно но. Компилятор выполнит его только в случае, если сможет. Для того, что он смог, сама функция и ее вызов должны быть описаны в одном файле.
На самом деле, если использование __attribute__((naked,noinline)) для branching_2 — это все-таки необходимость, то использование always_inline для branching — это блажь.
Посмотрите внимательно на код. Первым же оператором
setStackPointer(0x04,0xFF)
мы переставляем указатель стека (кстати, кто не в курсе, для ATmega168 0x04,0xFF — это и есть та самая правая граница области памяти (RAMEND), которую мы видели на картинке). Далее вызывается branching_2() и содержимое счетчика комманд пишется поверх того, что было сохранено в стеке. И тут же вдобавок 33 байта контекста. Иначе говоря, если даже метка входа в функцию branching() и была бы в нашей программе, мы бы сразу же ее и затерли. А что до выхода из функции… Функция branching() так построена, что штатного выхода из нее не случается никогда, а потому есть там возврат или нет… Совершенно не важно.
Я даже больше скажу. Вы думаете, что СИ, передавая управления в функцию main делает это с пустым стеком?… ЧУШЬ!…
В стеке на момент вызова функции main содержится… Никогда не догадаетесь, но это точка вызова функции main. Main, кстати определена с типом int по стандарту gcc. Кому функция main, живя на микроконтроллере, собирается возвращать значение — тайна великая. Эта глупость — следствие кросплатформенности компилятора. Тяжелое наследство его писишных товарищей…
(Примечание: Если конечно у вас нету полноценной операционки и файловой системы…)
Однако вернемся к нашему ветвителю.
void branching(void) //inline
{ setStackPointer(0x04,0xFF);
branching_2();
//В эту точку возвращаются новые потоки.
if (Taskcount==0) {Taskcount++;goto *programm1;}
if (Taskcount==1) {Taskcount++;goto *programm2;}
}
void branching_2 (void) //naked, noinlie
{ saveContext();
SPstore[1].i=copyContext(0x040A);
loadContext();
asm("ret");
}
Итак. Установили stackPointer на RAMEND, адрес которого равен 0x04FF. И этим велели проигнорировать все, что в стеке было раньше. Вызвали branching_2. Она не инлайновая. А значит в стек попал адрес точки возврата. При этом указатель стека съезжает на две позиции (адрес занимает два байта). Далее мы пользуемся функцией saveContext(), запихивая в стек 32 регистра общего назначения и SREG. В сумме указатель стека сместился уже на 35 позиций.
Следущая строчка SPstore[1].i=copyContext(0x040A); оперирует функцией, которая пока еще не написана. Эта функция берет 35 сохраненных байтов из стека и копирует их в другую область памяти. Значение 0x040A выбрано почти наобум. Это место далеко и от стека и от данных. Это середина кучи. Функция copyContext(0x040A), кроме прочего возвращает адрес в который надо установить указатель стека, чтобы второй стек можно было корректно считать.
И, да! Теперь у нас есть два стека в разных частях памяти. И есть проблема. Они одинаковые.
Поэтому, загрузив назад контекст первого процесса loadContext()
внимание: функция copyContext(0x040A) указатель стека не перемещает. Где он был на момент копирования, там он и остался.
———, мы говорим:
asm("ret");
Это ассемблерный вызов, который вернет нас по сохраненному при входе в branching_2()адресу.
Вызовется точка возврата и так как Taskcount равен 0, сработает строка
if (Taskcount==0) {Taskcount++;goto *programm1;}
(Примечание:Что касается goto *programm1, то это такой завуалированный вызов функции programm1. О нем чуть позже.)
Итак, мы вышли из ветвителя к первой программе. Сложно? Вроде не очень. Чего же я тут так подробно распинаюсь?
Дело все в том что работа функции branching() еще не закончена, ибо второй поток все еще в ней!!!
И чтобы понять, как второй поток будет из нее выбираться, посмотрим на вызов переключения контекста. В нашем же случае сигнал на переключение контекста дает таймер2.
Код выглядит так.
ISR(TIMER2_OVF_vect,ISR_NAKED)
{
saveContext(); // Сохраняем контекст.
if ((SPH*0x100+SPL)<0x420) // Очень глупый способ
// вычисления активного потока.
{
copyStackPointer(SPstore[1]);
loadStackPointer(SPstore[0]);
} // Сохраняем один SP
else
{ // И загружаем другой.
copyStackPointer(SPstore[0]);
loadStackPointer(SPstore[1]);
}
loadContext(); //Загружаем новый контекст.
asm("reti"); //Возврат из прерывания.
}
Функция обработчика прерывания топорная, как топор, и на диспетчер задач ни разу не тянет. Ее единственная цель демонстрация возможностей построения многозадачных приложений.
ISR(TIMER2_OVF_vect,ISR_NAKED).
ISR - это объявление обработчика прерывания.
TIMER2_OVF_vect - конкретизирует, мол что прерывание это при переполнении таймера 2.
(Таймер 2 уже включен в функции init(). Разрешение прерывания будет установленно в функции setup() при начале работы первого процесса.)
ISR_NAKED - это naked. Это разговор с компилятором, мол, не сохранять регистры, и руками не трогать...
Код особо комментариев не требует. Сохраняем контекст.
Если ((SPH*0x100+SPL)<0x420), тоесть процесс 2, то меняем шило на мыло, если нет то мыло на шило, путем сохранения текущего указатели стека одного процесса и загрузки указателя стека другого процесса. Наконец, загружаем контекст из стека. Поздравляю, мы в другом потоке и видим ассемблерный вызов asm("reti");.
Если вы посмотрите в справочник по системе команд AVR, то увидите, что это выход из прерывания. Выход, разумеется, в по тому адресу возврата, на который смотрит Stack Pointer в момент выполнения директивы. Фокус в том, что директиве reti без разницы, по чьему адресу выполнять возврат. Оставлен он родным прерыванием или же левой функцией, для неё разницы нет.
А Stack Pointer нашего второго потока, при его первом вызове, после загрузки контекста смотрит аккурат не куда-нибудь а на адрес, возврата из функции branching_2().
То есть в точку, которую я пометил как «//В эту точку возвращаются новые потоки.»
Ну, а чего? Копия же.
Так и срабатывает ветвление, ибо Taskcount со времен прошлого прохода равно 1.
Работает строка
if (Taskcount==1) {Taskcount++;goto *programm2;}
Вызывается programm2.
Вот таким вот образом. Разумеется, такой способ создания нового потока не единственно возможный, но, ИМХО, весьма простой.
Смена контекста теперь происходит при каждом прерывании счетчика Timer2. Удовольствие, кстати сказать, не дешевое. Обработчик прерываний съедает на себя около 140-160 тактов… (команды push и pop выполняются в 2 такта) В рамках работы микропроцессорной системы это целая вечность, и за это вытесняющую многозадачность не любят…
Примечание: Есть тут также такой момент. Ядро Arduino Использует Timer0 в качестве системного. А теперь еще Timer2 под функции многозадачности отвели. Всего-то один таймер остаётся у пользователя. Непорядок. Я упоминал о том, что ядровые функции Arduino можно подменять в пользовательских библиотеках. Совершенно последовательное решение — дополнить обработчик прерывания переполнения счётчика Timer0, дополнив его функцию переключением контекста. И тем самым освободить Timer2 для пользовательских процессов. Но в рамках данной статьи это было бы избыточно…
Теперь задача практически решена.
Дело за малым. Написать все еще не определенную функцию copyContext(0x040A), разобраться с оператором goto и изготовить демонстрационную программу.
Но cначала полный листинг файла main.cpp:
#include <Arduino.h>
#include "MirmPS.h"
ISR(TIMER2_OVF_vect,ISR_NAKED)
{
saveContext(); // Сохраняем контекст.
if ((SPH*0x100+SPL)<0x420) // Очень глупый способ
// вычисления активного потока.
{
copyStackPointer(SPstore[1]);
loadStackPointer(SPstore[0]);
} // Сохраняем один SP
else
{ // И загружаем другой.
copyStackPointer(SPstore[0]);
loadStackPointer(SPstore[1]);
}
loadContext(); //Загружаем новый контекст.
asm("reti"); //Возврат из прерывания.
}
volatile void programm1 (void);
volatile void programm2 (void);
volatile SPstore_t SPstore[2]; // Здесь храняться указатели стека
// сохраненных потоков.
volatile int Taskcount=0; // Это счетчик выходов из ветвителя.
void branching(void)__attribute__((always_inline));
void branching_2 (void)__attribute__((naked,noinline));
void branching(void)
{ setStackPointer(0x04,0xFF); // установка SP в RAMEND
branching_2(); // точка вызова процедуры
// копирования.
//В эту точку возвращаются новые потоки.
//векторы выхода потоков из ветвителя:
if (Taskcount==0) {Taskcount++;goto *programm1;}
if (Taskcount==1) {Taskcount++;goto *programm2;}
}
void branching_2 (void)
{ saveContext(); //Сохраняем
SPstore[1].i=copyContext(0x040A); //Копируем
loadContext(); //Загружаем
//т.к. функция naked, нужно явно объявить возврат
asm("ret"); //Возвращаемся.
}
void loop1(void);
void loop2(void); //Функции реализованы в скетче.
void setup(void);
int main(void) //Точка входа программы.
{
init(); //Настройка ядра Ардуино. В основном таймеры.
cli(); //init() разрешает прерывания. но
//нам они пока не нужны. Запретим.
branching();//Ветвитель потоков.
return 0; //Сюда программа не попадёт.
}
volatile void programm1(void){ //А это два наших потока.
setup(); sei(); //Первый поток вызывает также cодержит
for (;;) {loop1(); //функцию setup.И разрешает прерывания.
}
} //За их вызов ответственна
volatile void programm2 (void){
for (;;) {loop2();} //функция branching()
}
Повествование получилось длинным и в формат одной статьи уже не влезает.
Поэтому продолжение в другом месте.
10 комментариев на «“Вытесняющая многозадачность для Arduino”»
Спасибо! Замечательная тема и стиль изложения!
Спасибо, я старался :)…
Автор, Вы мой кумир!
>>В стеке на момент вызова функции main содержится… Никогда не догадаетесь, но это точка вызова функции main.
Объявлять main
__attribute__((__noreturn__)) main (void)
так пробовали?
>>Стек сохранять не будем.
Странно, логично если каждая задача имеет своё значение, которое загружают, если задача стала активной
StackItem SavedSP[PROCESS_QTY];
Сначала востанавливать SP, потом регистры, статус и PC (командой reti).
Нет, не пробовал… Спасибо.
Эммм… Не понял мысль…
Это я о том, что такой способ
установки нового SP — не лучшее решение. Если потоков несколько, то сколько if-ов надо будет писать?
Может лучше завести переменную-номер активной задачи и массив сохранённых значений SP.
… Странно, что этот вопрос вообще поднимается…
Конечно, именно так и надо делать :)…
первая статья на полгода разбирательств.
спасибо.
Спасибо большое!!! Отличная статья!
Есть понимание что ни кто не ответит но все же.
После применения всех действия, при компиляции получаю:
avr-gcc: error: unrecognized command line option ‘-assembler-with-cpp’
ARDUINO IDE 1:1.0.5-dfsg2-2
Kubuntu 14.04