
 Думаю, пришло время окинуть взглядом архитектуру ARM Cortex-M3 в целом и конкретно STM32, потому что это важно для понимания многих особенностей работы этих микроконтроллеров в будущем — например, тактирование и принцип работы DMA. Прежде, чем приниматься за более сложные темы, мы изучим внутренности МК и их взаимодействие друг с другом.
Думаю, пришло время окинуть взглядом архитектуру ARM Cortex-M3 в целом и конкретно STM32, потому что это важно для понимания многих особенностей работы этих микроконтроллеров в будущем — например, тактирование и принцип работы DMA. Прежде, чем приниматься за более сложные темы, мы изучим внутренности МК и их взаимодействие друг с другом.
Аппаратная модель Cortex-M3
Взглянем на схему Cortex-M3:
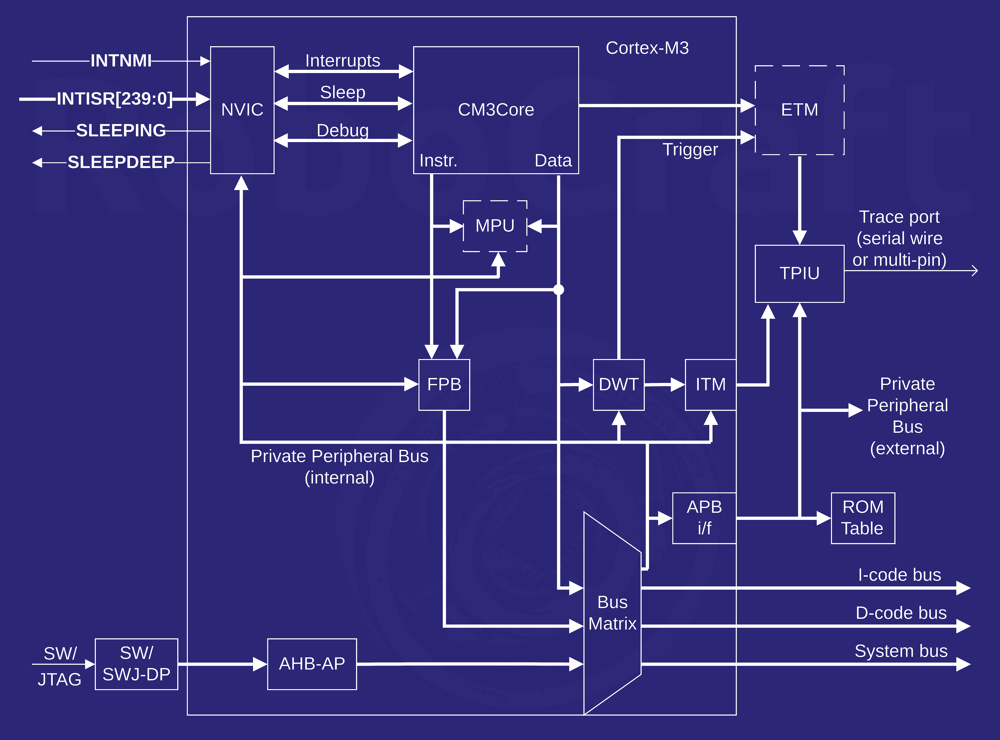
На ней обозначены «блоки», из которых состоит микроконтроллер, но на самом деле они взаимосвязаны и неотделимы друг от друга в реальной микросхеме. Более того, архитектура МК состоит из несколько уровней абстракции, а мы, не будучу профессиональными проектировщиками процессоров, будем рассматривать самый верхний и наименее детализированный во избежание опухания мозга. На этом уровне для нас наиболее важны три ключевых компонента.
Вычислительное ядро (CM3Core)
Выполняет инструкции, производит вычисления в своём АЛУ (арифметико-логическом устройстве). Его Гарвардская архитектура позволяет одновременно загружать инструкции и осуществлять доступ к памяти — благодаря этому, а также трёхступенчатому конвейеру, большинство инструкций выполняются за 1 такт. Ядро Cortex-M3 поддерживает набор инструкций Thumb-2, который содержит как 32-битные, так и 16-битные инструкции для сокращения объёма кода за счёт менее дальнобойных переходов; имеет 13 регистров общего назначения, снижая потребность в частом доступе к памяти.
Контроллер вложенных прерываний (NVIC)
Эта часть отвечает за генерацию прерываний на различные события: внешние — изменение логического уровня на входе ножки, пробуждение из режима сна; и внутренние — завершение приёма/отправки данных, переполнение счётчика таймера и т.п. Контроллер поддерживает до 240 прерываний и до 256 уровней приоритета, причём вход в обработчик прерывания занимает 12 тактов (сохранение стекового фрейма и регистров) и прерывания могут быть вложенными: если во время обработки прерывания возникает прерывание с меньшим приоритетом, то второе будет обработано через 6 тактов после обработки первого. Кроме того, существуют немаскируемые прерывания — NMI (Non-Masked Interrupts), которые невозможно сбросить, не обработав, и которые прерывают выполнение программы независимо от каких-либо условий. Такие прерывания генерируются при сбое внешнего источника тактирования (кварца, керамического резонатора) и при обнаружении некорректной инструкции.
Шинная матрица (Bus matrix)
Современные процессоры содержат множество различных шин, к которым подключаются остальные устройства системы. На заре компьютерной эпохи шиной (bus) называли просто пачку проводников, соединяющих несколько устройств с процессором, который мог одновременно работать лишь с одним устройством, а остальные в это время простаивали, так как шина была на всех одна. К тому же, все устройства были вынуждены работать на одной скорости (самого медленного устройства), что удерживало рост производительности систем.
Сегодня шины стали сложнее их число увеличилось на порядок. Раздельные шины дают возможность работать с несколькими устройствами одновременно, причём на разных скоростях: у каждой шины может быть своя скорость. Можно гибко управлять энергопотреблением, отключая неиспользуемые устройства и целые шины. Для управления всей этой оравой шин понадобилось вводить специальный контроллер, управляющий обменом данными между шинами и процессором.
Шинная матрица — это развитие идеи простого контроллера шины: здесь шины соединены так, что устройства могут взаимодействовать напрямую, не через ядро. Также она управляет доступом к не-выровненным данным (адреса которых не кратны 4, как принято в 32-битных архитектурах) и атомарным доступом к отдельным битам в специально выделенном диапазоне (технология bit-banding)
Архитектурой Cortex-M3 предусмотрены 4 шины, подключенных к матрице:
- ICode, для выборки инструкций и векторов прерываний — для пользовательского кода. 32-битная шина AHB-Lite типа.
- DCode, для выборки/записи данных и отладочного доступа — для пользовательского кода. 32-битная шина AHB-Lite типа.
- System, для выборки инструкций и векторов прерываний, а также выборки/записи данных и отладочного доступа в системном пространстве — для внутренних компонентов МК. 32-битная шина AHB-типа.
- PPB (Private Peripheral Bus), для выборки/записи данных и отладочного доступа — для периферии. 32-битная шина APB-типа.
AHB — это относительно новая спецификация для более производительных шин, так что шины этого типа используют, в основном, для связи высокоскоростных внутренних компонентов, а APB, как более медленную — для периферии типа GPIO, UART и пр.
Аппаратная модель STM32
Теперь рассмотрим конкретное воплощение Cortex-M3 — линейку микроконтроллеров STM32 на примере семейства STM32F10x (остальные отличаются незначительно). Спецификация Cortex-M3 включает в себя описание только базовой архитектуры, а периферия — уже на совести производителя МК, так что камни разных производителей могут отличаться по набору доступной периферии, по способу доступа к ней — набору управляющих регистров, их расположению в памяти и т.п., но в только в разрешённых пределах.
Чтобы разобраться с особенностями STM32, откроем RM0008 Reference manual (по всему семейству STM32F10x) и посмотрим схему МК линейки Connectivity line:
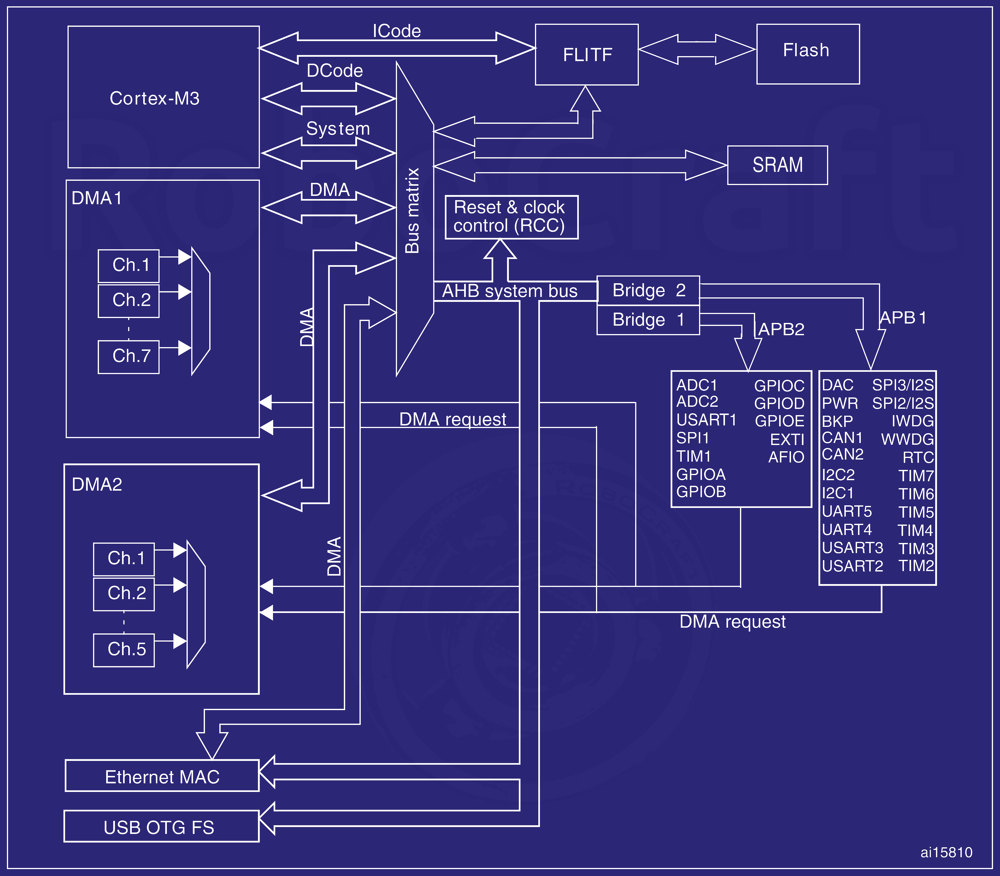
Как видно, здесь всё те же функциональные блоки, что и на предыдущей схеме, но добавились несколько шин и периферия. Периферия подключена к шине APB (PPB), которая соединена с AHB System bus через два так называемых «моста» (шины) APB1 и APB2, причём к каждому мосту подключен свой набор периферии. Фишка в том, что у этих мостов различаются максимальные рабочие частоты: APB2 может работать на частоте ядра (максимум 72 МГц для STM32F10x), а APB — максимум на половине частоты ядра (т.е. 36 МГц). Как видим, уже рассмотренные ранее GPIO подключены к более быстрой APB2, что позволяет работать им на частоте 50 МГц в МК с частотой 72 МГц; также сюда подключены АЦП (до 1 миллиона выборок в секунду), USART1 (до 4.5 МБит/с), SPI1 (до 18 МБит/с). Менее быстрая периферия подключена к APB1. Хотя есть и исключение — full-speed USB 2.0, имеющийся только в МК линейки Performance line, подключен к APB1.
Также можно заметить небольшой блок Reset & clock control (RCC), который управляет сбросом и тактированием контроллера, как видно из названия. Помните, в уроке Quickstart в примерах кода включался файл stm32f10x_rcc.h и перед использованием периферии нужно было включать её тактирование?
/* Включаем тактирование порта C */ RCC_APB2PeriphClockCmd(RCC_APB2Periph_GPIOC, ENABLE);
Так вот, в названии функции видны теперь уже знакомые нам RCC и APB2, и её смысл становится понятен: «RCC, включи тактирование на шине APB2 для периферии GPIOC».
Кроме того, RCC позволяет прямо в процессе работы МК переключаться между источниками тактирования — внешним кварцем или керамическим резонатором и встроенной откалиброванной RC-цепочкой, а также запрашивать у NVIC немаскируемое прерывание при сбое внешнего источника и переключаться на внутренний, увеличивая надёжность системы.
Интерфейс SDIO (в Performance line), а также Ethernet и USB OTG FS (в Connectivity line) подключены к шине AHB напрямую.
DMA
Direct Memory Access — это технология, позволяющая устройствам обмениваться данными друг с другом без участия ядра. Делается это так: контроллер DMA программируется так, чтобы осуществлять копирование данных из одной области памяти в другую, после чего требуется лишь запустить процесс — и контроллер сам начнёт копировать данные, а ядро МК в это время может выполнять другой код. При этом, копирование байта в регистр данных интерфейса SPI приводит к передаче этого байта по SPI, и таким образом можно готовить данные в виде пакетов по N байт, а потом скармливать их контроллеру DMA.
Работает это за счёт того, что контроллер подключен напрямую к шинной матрице по собственной шине и имеет прямой доступ ко всей памяти, включая память, на которую отображены управляющие регистры периферии. Контроллер в некотором смысле независим от ядра, и может сильно разгрузить последнее в том случае, если нужно обработать большое количество поступающей информации по нескольким интерфейсам. А для того, чтобы узнать о завершении передачи, контроллер может генерировать прерывания начала/конца передачи.
Программная модель
Вы уже знаете, что Cortex-M3 — полностью 32-битная архитектура. Это значит, что все шины 32-битные и все регистры процессорного ядра тоже. Что это даёт? Во-первых, большинство чисел, с которыми реально приходится работать программисту и программе, в большинстве случаев не превышают максимального значения 32-битного беззнакового числа — 4294967295. С другой стороны, эти числа часто бывают больше 255 — максимального значения 8-битного беззнакового числа. Таким образом, большинство вычислений даже с довольно большими числами даются 32-битному процессору легче, чем 8-битному, т.к. последнему приходится разбивать операцию с числами на несколько операций с меньшими их «кусками» размером по 8 бит. На сайте компании ARM Ltd. есть прикольный пример, показывающий преимущества 32-битного вычислительного ядра:
Comparing 16-bit multiply operations across processor architectures
8-bit example 16-bit example ARM Cortex-M --------------------------------------------------- MOV A, XL MOV R4,&0130h MULS r0,r1,r0 MOV B, YL MOV R5,&0138h MUL AB MOV SumLo,R6 MOV R0, A MOV SumHi,R7 MOV R1, B (Operands are moved to MOV A, XL and from a memory mapped MOV B, YH hardware multiply unit) MUL AB ADD A, R1 MOV R1, A MOV A, B ADDC A, #0 MOV R2, A MOV A, XH MOV B, YL MUL AB ADD A, R1 MOV R1, A MOV A, B ADDC A, R2 MOV R2, A MOV A, XH MOV B, YH MUL AB ADD A, R2 MOV R2, A MOV A, B ADDC A, #0 MOV R3, A
Суть такова: в ядрах Cortex-M умножение двух 16-битных чисел делается одной командой, ядра меньшей разрядности нервно курят вычисляют в сторонке. Конечно, пример специально выбран такой, чтобы опустить конкурентов пониже, но это на самом деле правда — ядра большей разрядности рулят (:
Рулёж тут ещё и в том, что с такой разрядностью можно адресовать 4 ГБ памяти — не нужно никаких ухищрений типа банков памяти и сегментной адресации, чтобы адресовать встроенную Flash-память, SRAM, периферию и ещё внешнюю память на отдельной микросхеме. А память в Cortex-M3 разделена на заранее оговоренные области, которые можно посмотреть в этой таблице:
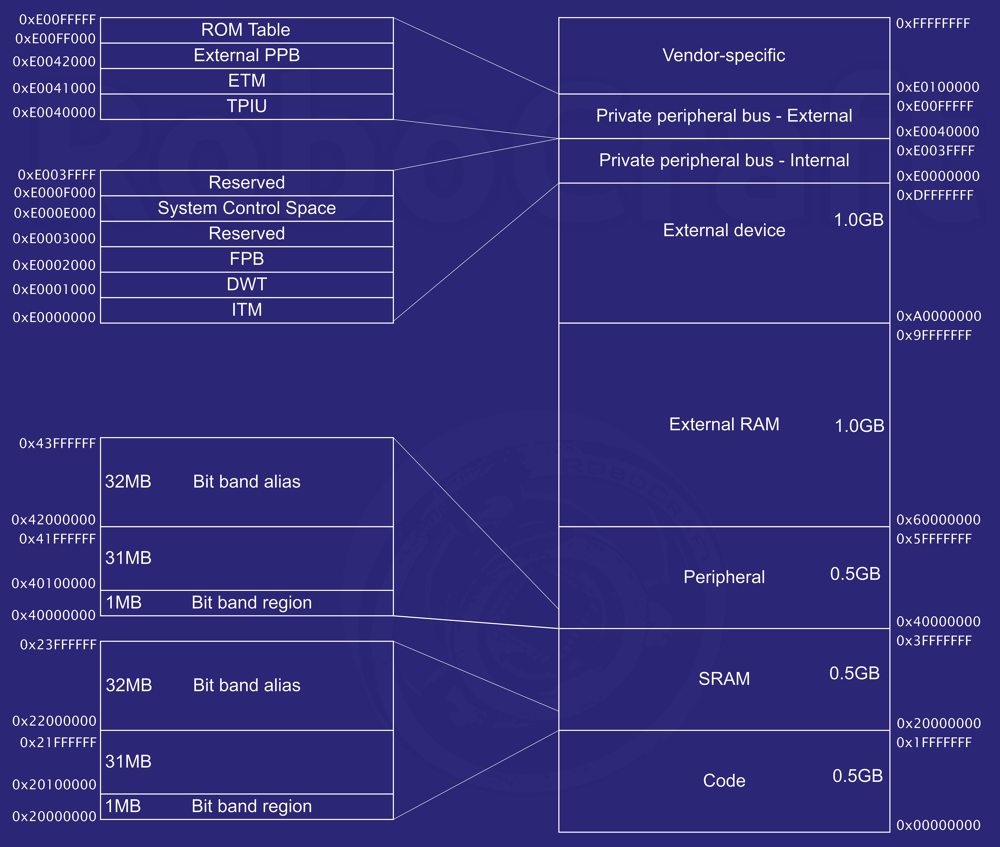
Доступ к пямяти можно осуществлять 32-битными словами, полусловами и байтами. Есть ограничения на некоторые регистры периферии, и об этом всегда пишут в Reference manual. Но это важно, по большому счёту, больше для пишущих на ассемблере.
Напоследок немного об ассемблере и инструкциях. Как обычно, доступны всё те же обычные инструкции типа копирования из памяти в регистры обратно, ветвлений и логических и арифметических операций. Но есть и некоторые уникальные особенности: например, большинство инструкций может быть выполнено условно. Нет, не только привычным способом:
cmp r2,r3 ; x == y
beq after
muls r0, r1, r0
add r0, r0, r2
after:
...
но и довольно оригинальным и необычным:
cmp r2,r3 ; x == y
itt eq
mulseq r0, r1, r0
addeq r0, r0, r2
...
Инструкция вида ITxxx делает от одной до 4х последующих инструкций условными, избавляя от необходимости в условных переходах, которые выполняются дольше. И подобных интересных инструкций ещё довольно много, включая инструкции для извлечения/установки битовых полей. Короче, рай для ассебмлерщика.
Но пока мы оставим это истинным мастерам кода и доверимся компилятору, который зачастую знает лучше нас все особенности архитектуры, а уж применять всякие хитрые приёмчики ему не составит никакого труда — нужны какие-то доли секунды для оптимизации даже приличного по размерам кода.
Ну, а пока новая информация обрабатывается вашими головными процессорами, я пошёл черкать про таймеры (:
0 комментариев на «“STM32: Урок 5 — Архитектура”»
Спасибо за тяжелый труд!
До этого читал как не зарегистрированный. Теперь хоть могу поблагодарить.
Год назад потребовалось создать устройство с нуля до уровня прототипа — попытался освоить STM32 сходу при нулевых знаниях. Сдался на второй неделе — ушел на avr&arduino. Сложность для новичков напомнила шутку про , хотя как раз ее удалось освоить сходу. Но прототип вот уже скоро будет готов и на второй или третей его итерации не оставляю надежд переделать на STM32 или на чем то по мощнее.
К слову, ST делают ещё и Cortex-M4, а там за 200 р можно взять камень с частотой 168 МГц, с набором DSP-инструкций, и во вполне паяемом корпусе (:
Почему 16 битных? 16-битные тоже есть, но приведенный MULS перемножает два 32-битных. Есть и команда для получения 64-битного результата — MULLS, в которой указываются два входных и два выходных регистра.
В приведённом примере от компании ARM сравнивается перемножение именно 16-битных величин. Да, команда MUL перемножает два 32-битных числа, но результат-то всё равно 32-битный, т.е. нет смысла перемножать числа больше, чем 16-бит. Разве только умножать 20-битное на 12-битное, 24-битное на 8-битное и т.д. в таком же духе.
А можно ещё добавить описание особенностей микроконтроллеров STM32L серии? У них система управления питанием куда более продвинутая и запутанная.
Увы, но вряд ли я это сделаю в ближайшее время. Я решил не заниматься пока другими семействами МК, т.к. банально не способен в одиночку двигать курс с хоть сколько-нибудь приемлемой скоростью, параллельно изучая ещё одно или более семейств. Так что могу только пожелать удачи
*смайл, смущённо сверлящий пальцем пол*