
![]() Вчера на хабре появилась интересная статья про сравнение изображений — «Выглядит похоже». Как работает перцептивный хэш и я сразу же загорелся повторить этот алгоритм 🙂
Вчера на хабре появилась интересная статья про сравнение изображений — «Выглядит похоже». Как работает перцептивный хэш и я сразу же загорелся повторить этот алгоритм 🙂
Итак, идея алгоритма получения хеша изображения:
1. Уменьшить размер (cvResize()), чтобы оставить только значимые объекты картинки (избавление от высоких частот).
В изображениях, высокие частоты обеспечивают детализацию, а низкие частоты показывают структуру. Большая фотография содержит много высоких частот, а маленькая картинка целиком состоит из низких.
Уменьшаем картинку до 8х8, тогда общее число пикселей составит 64 и хэш будет соответствовать всем вариантам изображения, независимо от их размера и соотношения сторон.
2. Убираем цвет. Переводим изображение, полученное на предыдущем шаге в градации серого. (cvCvtColor()) Т.о. хэш уменьшается втрое: со 192 ( по 64 значений трёх каналов — красного, зелёного и синего) до 64 значений яркости.
3. Находим среднее среднее значение яркости получившегося изображения. (cvAvg())
4. Бинаризация картинки. (cvThreshold()) Оставляем только те пиксели, которые больше среднего (считаем их за 1, а все остальные за 0).
5. Строим хэш. Переводим полученные 64 значений 1 и 0 картинки в одно 64-битное значение хэша.
Далее, если вам нужно сравнить две картинки, то просто строите хэш для каждой из них и подсчитываете количество разных битов (с помощью расстояния Хэмминга).
Расстояние Хэмминга — число позиций, в которых соответствующие цифры двух двоичных слов одинаковой длины различны.
Нулевое расстояние означает, что это, скорее всего, одинаковые картинки, а другие величины характеризуют насколько сильно они отличаются друг от друга 🙂
Из функций, которые нам понадобятся мы пока не использовали функцию cvAvg():
CVAPI(CvScalar) cvAvg( const CvArr* arr, const CvArr* mask CV_DEFAULT(NULL) );
— вычисляет среднее значение всех элементов массива (отдельно для каждого канала)
arr — указатель на массив
mask — маска
формулы:
N = Summ (mask(I)!=0 ) mean = (1/N)*Summ( arr(I) )
Вот что у меня получилось:
вычисление хеша происходит в функции calcImageHash(), а рассчёт расстояния Хемминга между двумя хэшами происходит в функции calcHammingDistance() (взял из английской википедии 🙂
//
// сравнение похожих картинок
// на основе статьи: «Выглядит похоже». Как работает перцептивный хэш
// http://habrahabr.ru/blogs/image_processing/120562/
//
// https://robocraft.ru
//
#include <cv.h>
#include <highgui.h>
#include <stdlib.h>
#include <stdio.h>
// рассчитать хеш картинки
__int64 calcImageHash(IplImage* image, bool show_results=false);
// рассчёт расстояния Хэмминга
__int64 calcHammingDistance(__int64 x, __int64 y);
int main(int argc, char* argv[])
{
IplImage *object=0, *image=0;
char obj_name[] = "cat2.jpg";
char img_name[] = "cat.jpg";
// имя объекта задаётся первым параметром
char* object_filename = argc >= 2 ? argv[1] : obj_name;
// имя картинки задаётся вторым параметром
char* image_filename = argc >= 3 ? argv[2] : img_name;
// получаем картинку
object = cvLoadImage(object_filename, 1);
image = cvLoadImage(image_filename, 1);
printf("[i] object: %s\n", object_filename);
printf("[i] image: %s\n", image_filename);
if(!object){
printf("[!] Error: cant load object image: %s\n", object_filename);
return -1;
}
if(!image){
printf("[!] Error: cant load test image: %s\n", image_filename);
return -1;
}
// покажем изображение
cvNamedWindow( "object");
cvShowImage( "object", object );
cvNamedWindow( "image");
cvShowImage( "image", image );
// построим хэш
__int64 hashO = calcImageHash(object, true);
//cvWaitKey(0);
__int64 hashI = calcImageHash(image, false);
// рассчитаем расстояние Хэмминга
__int64 dist = calcHammingDistance(hashO, hashI);
printf("[i] Hamming distance: %I64d \n", dist);
// ждём нажатия клавиши
cvWaitKey(0);
// освобождаем ресурсы
cvReleaseImage(&object);
cvReleaseImage(&image);
// удаляем окна
cvDestroyAllWindows();
return 0;
}
// рассчитать хеш картинки
__int64 calcImageHash(IplImage* src, bool show_results)
{
if(!src){
return 0;
}
IplImage *res=0, *gray=0, *bin =0;
res = cvCreateImage( cvSize(8, 8), src->depth, src->nChannels);
gray = cvCreateImage( cvSize(8, 8), IPL_DEPTH_8U, 1);
bin = cvCreateImage( cvSize(8, 8), IPL_DEPTH_8U, 1);
// уменьшаем картинку
cvResize(src, res);
// переводим в градации серого
cvCvtColor(res, gray, CV_BGR2GRAY);
// вычисляем среднее
CvScalar average = cvAvg(gray);
printf("[i] average: %.2f \n", average.val[0]);
// получим бинарное изображение относительно среднего
// для этого воспользуемся пороговым преобразованием
cvThreshold(gray, bin, average.val[0], 255, CV_THRESH_BINARY);
// построим хэш
__int64 hash = 0;
int i=0;
// пробегаемся по всем пикселям изображения
for( int y=0; y<bin->height; y++ ) {
uchar* ptr = (uchar*) (bin->imageData + y * bin->widthStep);
for( int x=0; x<bin->width; x++ ) {
// 1 канал
if(ptr[x]){
// hash |= 1<<i; // warning C4334: '<<' : result of 32-bit shift implicitly converted to 64 bits (was 64-bit shift intended?)
hash |= 1i64<<i;
}
i++;
}
}
printf("[i] hash: %I64X \n", hash);
if(show_results){
// увеличенные картинки для отображения результатов
IplImage* dst3 = cvCreateImage( cvSize(128, 128), IPL_DEPTH_8U, 3);
IplImage* dst1 = cvCreateImage( cvSize(128, 128), IPL_DEPTH_8U, 1);
// показываем картинки
cvNamedWindow( "64");
cvResize(res, dst3, CV_INTER_NN);
cvShowImage( "64", dst3 );
cvNamedWindow( "gray");
cvResize(gray, dst1, CV_INTER_NN);
cvShowImage( "gray", dst1 );
cvNamedWindow( "bin");
cvResize(bin, dst1, CV_INTER_NN);
cvShowImage( "bin", dst1 );
cvReleaseImage(&dst3);
cvReleaseImage(&dst1);
}
// освобождаем ресурсы
cvReleaseImage(&res);
cvReleaseImage(&gray);
cvReleaseImage(&bin);
return hash;
}
// рассчёт расстояния Хэмминга между двумя хэшами
// http://en.wikipedia.org/wiki/Hamming_distance
// http://ru.wikipedia.org/wiki/Расстояние_Хэмминга
//
__int64 calcHammingDistance(__int64 x, __int64 y)
{
__int64 dist = 0, val = x ^ y;
// Count the number of set bits
while(val)
{
++dist;
val &= val - 1;
}
return dist;
}
скачать иcходник (simpleImageHash.cpp)
пример рассчёта хеша: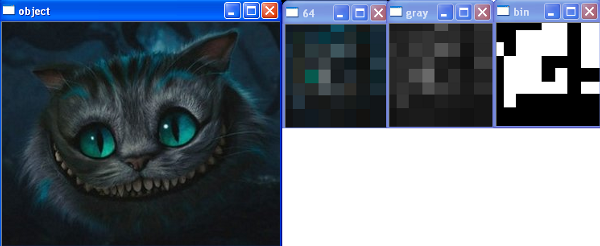
результат сравнения двух моих фотографий:

[i] object: cat2.jpg [i] image: cat.jpg [i] average: 36.88 [i] hash: 2BE2E8E3D3CB0 [i] average: 30.69 [i] hash: 48847E5536130C10 [i] Hamming distance: 25
хм… разные :)))
Ссылки
«Выглядит похоже». Как работает перцептивный хэш
http://ru.wikipedia.org/wiki/Расстояние_Хэмминга
http://en.wikipedia.org/wiki/Hamming_distance
http://phash.org
12 комментариев на «“OpenCV — Сравнение изображений через хэш”»
Почитайте лучше на тему Feature-Based Image Analysis и Image Similarity Metric; объясняют как это делается в реальных системах. Слишком уж общо допущение, что низкие частоты кодируют структуру.
Спасибо! как-нибудь почитаю 🙂
Вообще мне оказалась интересна задача скорее не построения такой свёртки, а её робастной минимизации. В идеале хотелось некую универсальную фнукцию по результату которой можно будет именовать файлы картинок и делая обычную сортировку получать более-менее надёжное группирование схожих (игнорируя шум, повороты, масштаб итп).
Кстати термин «хеш», по-моему, не очень подходит, т.к. под хешами обычно подразумевают свёртку, уникальную для исходных данных, чтобы не было хэш-коллизий, а перцептивные идентификаторы наоборот подразумевают получение одинакового результата для разных (до определённого критерия схожести) картинок.
hash |= 1i64<<i; как это написать на MacOs в Xcode
if(ptr[x]){
// hash |= 1<<i; // warning C4334: ‘<<‘: result of 32-bit shift implicitly converted to 64 bits (was 64-bit shift intended?)
hash |= 1i64<<i;
}
Как это написать на c#?
перечитайте статью, чтобы понять суть работы алгоритма.
см. п. 5:
— все пиксели одноканального бинарного изображения и если пиксель белый, то устанавливаем соответствующий бит 64-битной переменной.
У меня на c# значения хэша получаются десятизначные и нет ни одной буквы, только цифры. Для второй картинки с котом, которая более оранжевая хэш отрицательое число о_О
Спасибо за код, но деревянный голова не понимать:
код устанавливает i-й бит в 64-х битной переменной hash.
отталкивался отсюда:
Спасибо!
ps теперь думаю, как бы это на большой коллекции сделать попроще…
видимо?: